What Are Descriptive Statistics? A Practical Introduction
Common concepts covered in descriptive statistics include mean, median, mode, variance, standard deviation, range, interquartile range (IQR), skewness, kurtosis, percentiles, and quartiles.
Descriptive statistics are methods used to summarize and organize data so it becomes easier to understand. Instead of looking at raw numbers, you get a clear picture of what the data is actually saying.
They help you identify patterns, detect outliers, and understand how values are distributed. In every data analysis project, descriptive statistics are the first step before making predictions or decisions.
Descriptive statistics do not predict the future. They help you understand the present data clearly so better decisions can be made.
🔑 Key Takeaways
A quick summary of the most important ideas in descriptive statistics. Keep these in mind when analyzing any dataset.
Descriptive statistics simplify data. They turn raw numbers into clear, usable insights.
Central tendency shows the typical value. Mean, median, and mode each describe the center differently.
Spread matters as much as averages. Standard deviation and IQR show how consistent or varied data is.
Outliers can distort interpretation. Median and IQR help reduce their impact.
Distribution shape reveals hidden patterns. Skewness and percentiles help understand data behavior.
Always start with descriptive statistics. They are the foundation of every data analysis workflow.
How to Think About Any Dataset
Before jumping into formulas, it helps to follow a simple mental framework. Almost every dataset can be understood by answering three questions.
- 1. Where is the center? Use mean, median, or mode to find the typical value.
- 2. How spread out is the data? Use standard deviation or IQR to measure variability.
- 3. What does the shape look like? Use skewness and kurtosis to understand distribution patterns.
This step-by-step approach keeps your analysis focused and prevents you from jumping to conclusions too early.
Why Descriptive Statistics Matter
Raw data rarely tells its own story. Descriptive statistics turn messy spreadsheets into something understandable. They reveal the center of the data, how spread out the values are, and whether the distribution looks symmetrical or lopsided.
You use them in exploratory data analysis (EDA) to spot outliers, check assumptions, and decide which advanced methods to apply later. Students, analysts, researchers, and data scientists all rely on these measures daily.
Three Main Categories
| Category | What It Shows | Measures |
|---|---|---|
| Central Tendency | Where data clusters | Mean, Median, Mode |
| Dispersion | Spread of data | Range, Variance, SD, IQR |
| Shape | Distribution behavior | Skewness, Kurtosis |
Measures of Central Tendency
These measures show the typical or central value in a dataset.
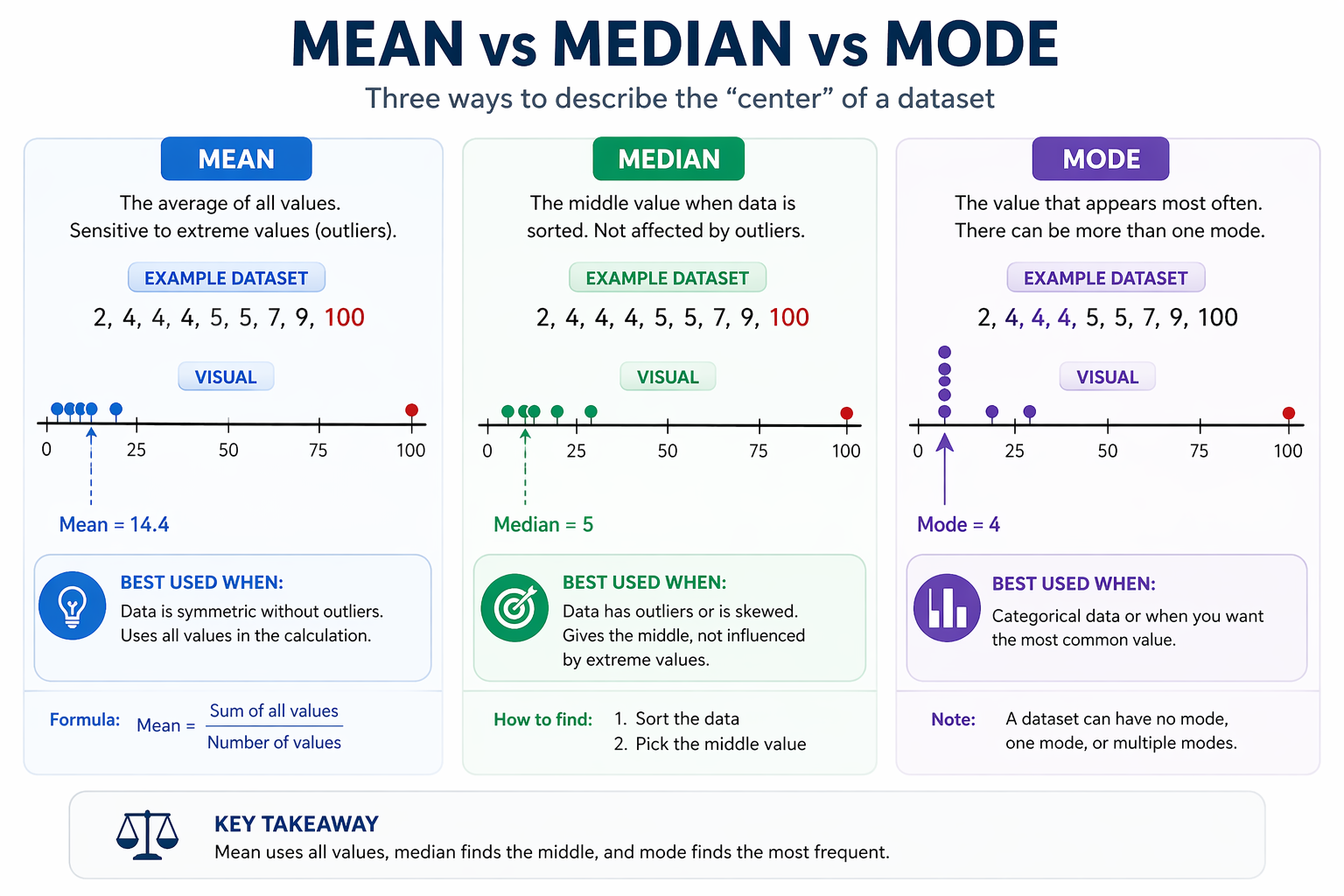
Mean
The mean is the arithmetic average.
Formula:
$ \bar{x} = \frac{\sum x_i}{n} $
Example – Exam Scores
Scores: 65, 72, 75, 78, 80, 82, 85, 88, 90, 95
Sum = 810
$ \bar{x} = \frac{810}{10} = 81 $
The average score is 81. The mean works well with symmetrical data but gets pulled strongly by extreme values.
Median
The median is the middle value after sorting the data.
Sorted scores: 65, 72, 75, 78, 80, 82, 85, 88, 90, 95
Median = (80 + 82) / 2 = 81
Change one score to 200 and the mean jumps to 90.5, but the median stays at 82. That resistance to outliers makes the median useful for skewed or messy data.
Original data: 65, 72, 75, 78, 80, 82, 85, 88, 90, 95
Mean = 81, Median = 81
With an outlier (replace 95 with 200):
65, 72, 75, 78, 80, 82, 85, 88, 90, 200
Mean = 90.5 (moves a lot)
Median = 81 (barely changes)
The mean reacts to extreme values because it uses every number. The median only depends on the middle position, which makes it more stable.
Mode
The mode is the most frequent value.
Shoe sizes in a class: 7, 8, 8, 8, 9, 9, 10, 11
Mode = 8
Some datasets have two modes (bimodal) or several (multimodal). Mode works especially well with categorical data such as favorite colors or product types.
Knowing the center is useful, but it does not tell the whole story. Two datasets can have the same average and still behave very differently. That is why we also need to measure how spread out the data is.
Measures of Dispersion
These tell you how spread out the data points are.
Same exam scores dataset: 65, 72, 75, 78, 80, 82, 85, 88, 90, 95
Which Measure Should You Use?
Different situations call for different statistical measures. Choosing the right one depends on the shape of your data and whether outliers are present.
- Use the mean when your data is roughly symmetrical and does not contain extreme outliers.
- Use the median when your data is skewed or includes outliers. It gives a more reliable “typical” value.
- Use the mode when working with categorical data or when you want to know the most common value.
- Use standard deviation when your data follows a normal (bell-shaped) distribution and you want to measure variability.
- Use IQR when your data contains outliers or is not normally distributed. It focuses on the middle 50%.
In practice, analysts often look at both the mean and median together. If they differ significantly, it is a strong signal that the data may be skewed.
Try It Yourself
Work through this small dataset to check how well you understand the concepts.
Dataset: 12, 15, 15, 18, 20, 22, 25
Now try answering these:
- What is the mean?
- What is the median?
- What is the mode?
- What is the range?
- Is the data skewed or fairly balanced?
Take a moment before checking answers mentally. The goal is to recognize patterns, not just calculate numbers.
Range
Formula: Range = Maximum − Minimum
Range = 95 − 65 = 30
Simple, but it only looks at the two extremes.
Variance and Standard Deviation
Variance averages the squared differences from the mean.
One drawback is that variance is measured in squared units, which can be hard to interpret. That is why standard deviation is often preferred, since it brings the value back to the original scale.
Sample variance formula:
$ s^2 = \frac{\sum (x_i - \bar{x})^2}{n-1} $
For the scores, variance ≈ 93.33
Standard deviation:
$ s = \sqrt{93.33} \approx 9.66 $
A standard deviation of roughly 9.7 means most scores fall within about 10 points of the average.
Interquartile Range (IQR)
IQR focuses on the middle 50% of the data and resists outliers.
Q1 = 75, Q3 = 88
IQR = 88 − 75 = 13
Many analysts flag values below Q1 − 1.5×IQR or above Q3 + 1.5×IQR as potential outliers.
Five-Number Summary
A five-number summary provides a quick overview of a dataset using five values:
- Minimum
- Q1 (25th percentile)
- Median (Q2)
- Q3 (75th percentile)
- Maximum
This summary is commonly used in box plots to visualize distribution and detect outliers.
Shape of the Distribution
After understanding the spread, the next step is to look at the overall pattern of the data. This helps reveal whether values are balanced or skewed in one direction.
Skewness
Skewness describes asymmetry.
Salary example (in thousands): 45, 48, 52, 55, 60, 65, 70, 120
Mean ≈ 64.4, Median = 57.5 → positive (right) skew. The single high salary pulls the tail to the right.
Kurtosis
Kurtosis shows how heavy the tails are and how peaked the center is compared with a normal distribution.
High kurtosis (leptokurtic): sharp peak, heavy tails
Low kurtosis (platykurtic): flatter peak, lighter tails
Normal distribution: mesokurtic (kurtosis ≈ 3)
Percentiles and Quartiles
Percentiles divide data into 100 equal parts and show how a value compares to the rest of the dataset. Quartiles are special percentiles that split data into four equal parts.
- Q1 (25th percentile): 25% of values fall below this point
- Q2 (50th percentile / median): Middle value of the dataset
- Q3 (75th percentile): 75% of values fall below this point
For example, if the 75th percentile score in an exam is 88, it means 75% of students scored 88 or lower.
Percentiles are widely used in real life to compare performance, such as exam rankings, income distribution, and health metrics like growth charts.
They also form the basis of box plots, where quartiles help visualize spread, central value, and potential outliers in one view.
Descriptive vs Inferential Statistics
So far, everything focuses on describing the data you already have. The next step is understanding how this differs from making predictions or generalizations.
Descriptive statistics summarize the data you actually have. Inferential statistics use that summary to make predictions or test claims about a larger population.
| Aspect | Descriptive Statistics | Inferential Statistics |
|---|---|---|
| Goal | Describe what the data shows | Draw conclusions about a population |
| Focus | Current dataset | Generalization from sample |
| Typical tools | Mean, SD, IQR | Confidence intervals, hypothesis tests |
Real-World Uses
- Retail teams track average daily sales and sales variability
- Hospitals monitor recovery times and blood pressure ranges
- Teachers review score distributions to spot learning gaps
- Analysts calculate investment risk using standard deviation of returns
Full Example: Analyzing a Dataset End-to-End
Let’s bring everything together and analyze a single dataset step by step using all the key descriptive statistics.
Dataset: 10, 12, 14, 15, 15, 16, 18, 20, 22, 60
Step 1: Central Tendency
Mean = 19.2 (pulled upward by the extreme value 60)
Median = 15.5 (more representative of the center)
Mode = 15 (most frequent value)
Step 2: Spread
Range = 60 − 10 = 50
Standard deviation is relatively high because of the outlier
IQR focuses on the middle values and ignores the extreme value
Step 3: Shape
The data is positively skewed due to the value 60 pulling the distribution to the right.
Final Interpretation
Although the mean suggests an average around 19, the median shows the true center is closer to 15–16. This indicates the dataset is not symmetric and contains an outlier that distorts the mean.
Summary Table
| Measure | Category | What It Shows | Sensitive to Outliers |
|---|---|---|---|
| Mean | Central Tendency | Arithmetic average | Yes |
| Median | Central Tendency | Middle value | No |
| Mode | Central Tendency | Most common value | No |
| Range | Dispersion | Total spread | Yes |
| Standard Deviation | Dispersion | Typical distance from mean | Yes |
| IQR | Dispersion | Spread of middle 50% | No |
| Skewness | Shape | Asymmetry | Yes |
Conclusion
Descriptive statistics are the starting point of every meaningful data analysis. They help you quickly understand what a dataset is saying before you move into deeper analysis or predictions.
The key idea is simple: always look at the center, spread, and shape of your data before making any decisions. These three perspectives give you a complete picture of what is really happening.
If you remember just one thing, let it be this: the mean tells you the average, the median tells you the typical value, and the standard deviation tells you how consistent the data is.
Once you are comfortable with these basics, you can confidently move into more advanced topics like probability, hypothesis testing, and predictive analysis.
FAQs
It is the set of methods used to summarize and describe the main features of a dataset.
Use the median when the data contains outliers or is skewed. The mean works better with symmetrical data.
Standard deviation is in the same units as the original data, making it easier to interpret.
The data has a longer tail on the right side. Most values cluster on the lower end, with a few unusually high ones.
Yes. Mode and frequency counts are the main tools for categorical variables.
It helps identify potential outliers in box plots.
Read More Articles
Computed Mean vs Actual Mean
Understand the difference between computed mean and actual mean with clear explanations and examples.
Read More →Mean (Average)
Learn how the mean is calculated and why it is the most commonly used measure of central tendency.
Read More →Median
Discover how the median represents the middle value and when it is more useful than the mean.
Read More →